

概要
「Link Reader」プラグインは、Webページ、PDF、PPT、さまざまなリンクの内容から情報収集できます。
できること
Webページ、YouTube、PDF、PPT、画像、Word文書などのリンクから情報を取得することができます
実例
例としてOpenAI社のGPT-4 APIのニュースから内容を要約
プロンプト:
下記のURLの内容を抽出して下さい
https://openai.com/blog/gpt-4-api-general-availability結果:
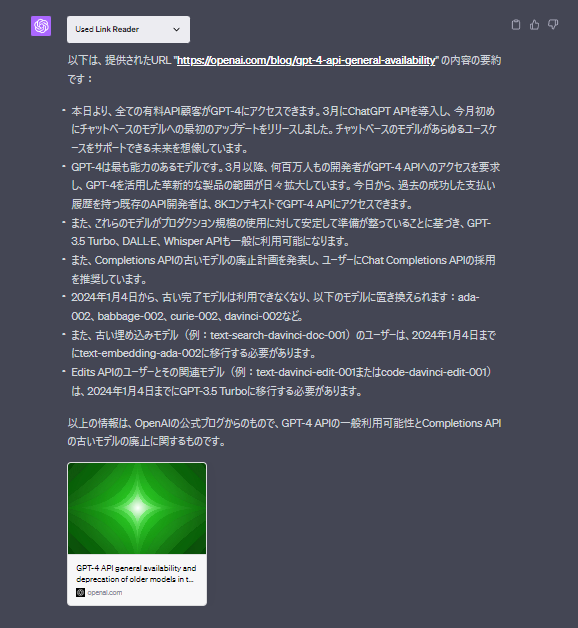
要点をまとめて教えてくれました。
英語のページですが、プロンプトは日本語なので日本語に翻訳して答えてくれました。。
次にPDFファイルの内容を要約します。
例として、経産省のAI導入ガイドブックのPDFの内容を要約してみます。
プロンプト:
下記のURLの内容を抽出して下さい https://www.meti.go.jp/policy/it_policy/jinzai/AIguidebook_DemandForecast_MFG_FIX.pdf結果:
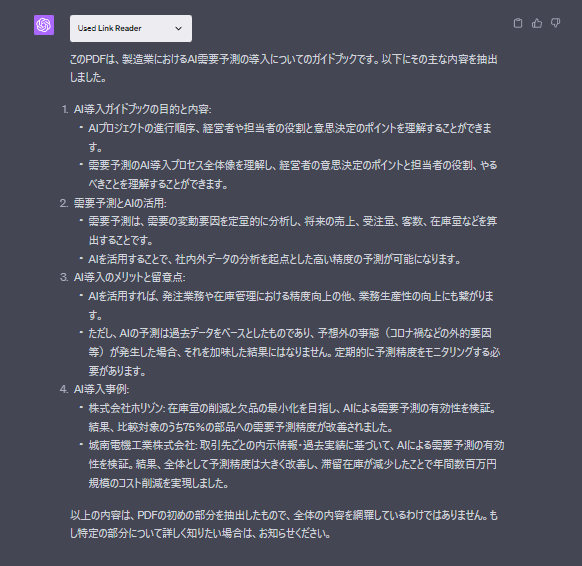
84ページあるPDFでしたが、上手く要約してくれています。
最後に画像からテキストを抽出しようと思います。
MicrosoftAzureの解説記事の見出し画像からテキストを抽出してみます。
プロンプト:
下記のURLのテキストの内容を抽出して下さい
https://biztechdx.com/wp-content/uploads/2023/07/10.png結果:
完璧な結果でした。
おすすめ度
いくつか試してみましたが素晴らしい結果でした。
間違いなくオススメできるプラグインの一つです。
オススメ度:★★★







