NTT版LLMの概要
近年、ChatGPTを始めとする大規模言語モデル*1に大きな注目が集まっておりますが、これらは膨大な知識をモデル内に有することで高い言語処理性能を示す一方、学習に要するエネルギーは、原発1基1時間分の電力量が必要*2とも言われており、また、運用には大規模なGPUクラスタを必要とし様々な業界に特化するためのチューニングや推論にかかるコストが膨大であることから、サステナビリティおよび企業が学習環境を準備するための経済的負担面で課題があります。
NTTでは、これらの課題を解決する研究開発を進め、今回、軽量でありながら世界トップレベルの日本語処理性能を持つ大規模言語モデル「tsuzumi*2」を開発しました。「tsuzumi」のパラメタサイズは6~70億と軽量であるため、市中のクラウド提供型LLMの課題である学習やチューニングに必要となるコストを低減します。「tsuzumi」は英語と日本語に対応し、1GPUやCPUでの推論動作を実現します。更に、「tsuzumi」は視覚や聴覚といったモーダルに対応し、特定の業界や企業組織に特化したチューニングが可能です。
NTTグループでは、「tsuzumi」を用いた商用サービスを2024年3月に開始し、また今後の「tsuzumi」の研究開発については、さらなるマルチモーダル機能*3を追加することで新しい価値を創出する研究開発を推進しています。本稿では「tsuzumi」の4つの特長を紹介いたします。
軽量なLLM
日本語と英語に対応 ~特に日本語が得意なLLM~
柔軟なチューニング ~基盤モデル+アダプタ~
マルチモーダル ~言語+視覚・聴覚・ユーザ状況理解~
軽量なLLM
2022年11月30日にOpenAI社が公開した「ChatGPT」の登場以降、ユーザとの自然な対話をサポートし、多くのトピックに関して人間以上に幅広いタスクに対応できる対話型AIが注目を集めています。こういった対話型AIを実現している言語モデルは、大規模なデータセットと計算リソースを活用して学習された膨大なパラメタ数のモデルを用いることで、自然な言語生成のタスクに優れた性能を発揮しています。
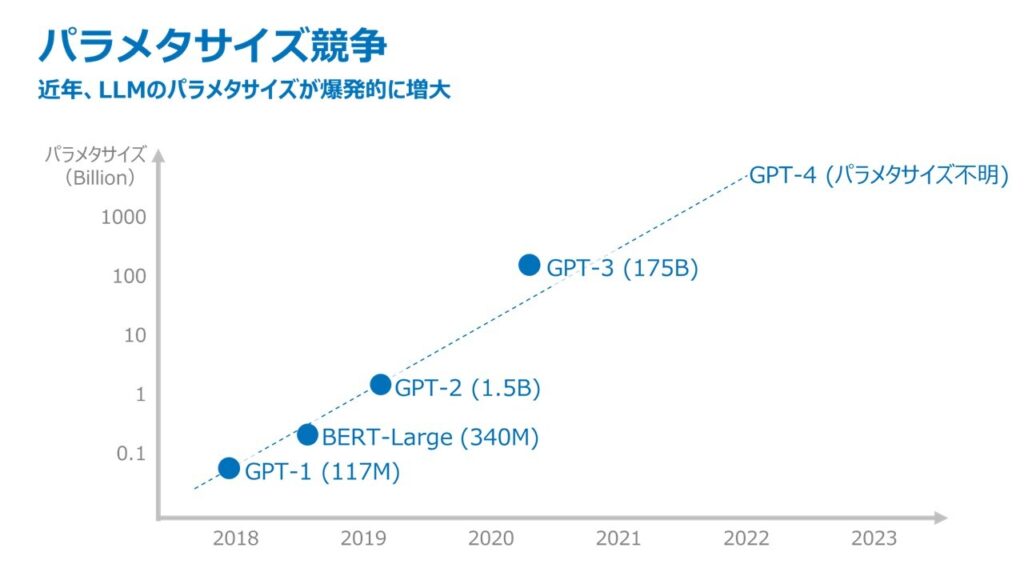
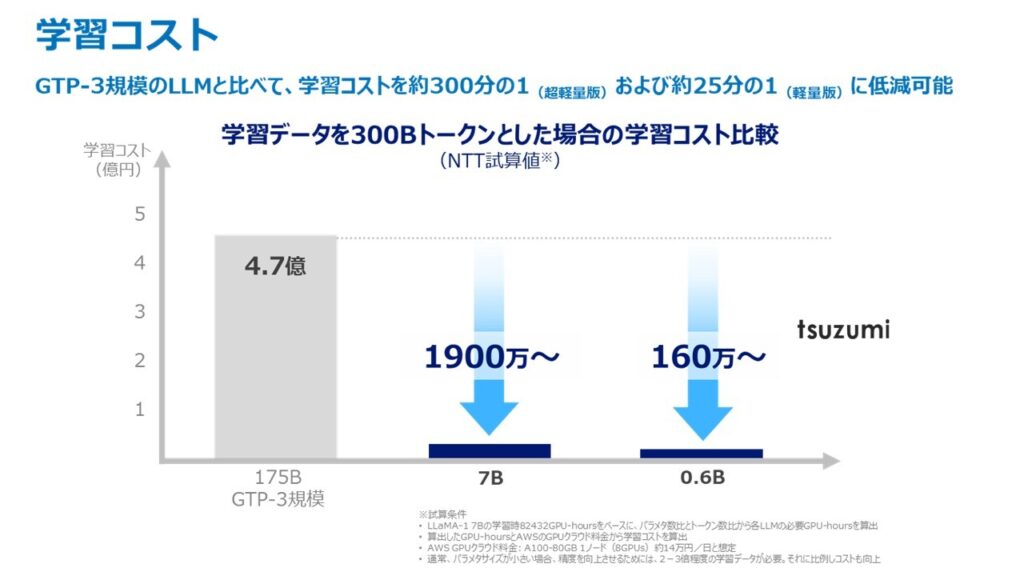
図2 tsuzumiとGPT-3の学習コスト比較
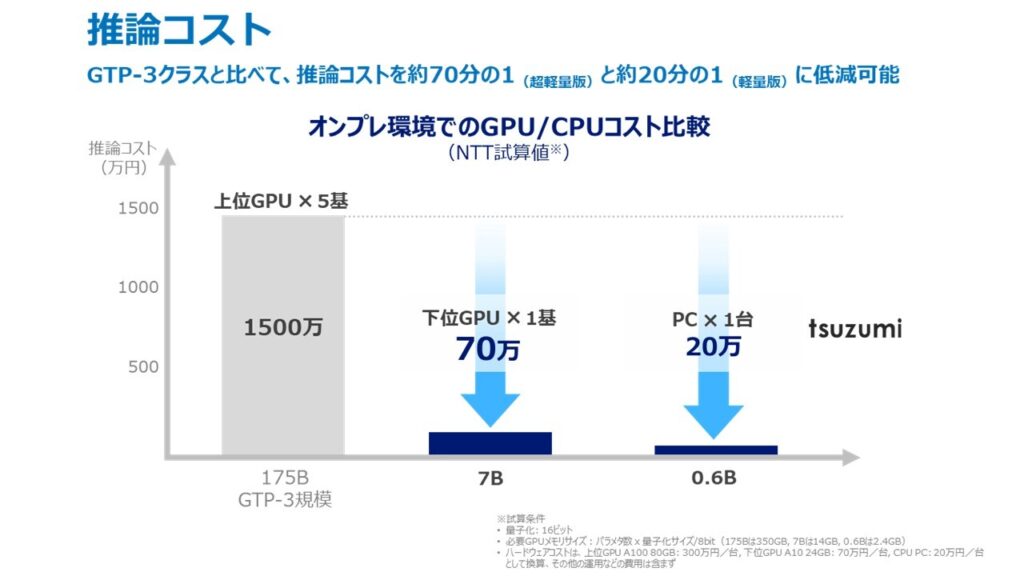
図3 tsuzumiとGPT-3の推論コスト比較
このパラメタの増大は、性能向上につながる一方で計算リソースの増加、エネルギー消費量の増加などの課題も伴います。例えば、GPT-3規模のモデルの学習には約1300MWh(原発1基1時間分)の電力量*4が必要と言われています。「tsuzumi」はパラメタサイズを増加させるかわりに、日本語学習データの質と量を向上させるアプローチにより、非常に軽量なモデルで高い日本語処理能力を実現しています。
「tsuzumi」のパラメタサイズは2023年10月時点で軽量版の70億(7B)と、超軽量版の6億(0.6B)の2種類をそろえ、OpenAI社 GPT-3の1750億(175B)に対しておよそ300分の1および25分の1のサイズです。軽量版は1GPUで、超軽量版はCPUで高速に推論動作可能なモデルサイズにすることで、実用上必要となる追加学習や推論に必要なコストを抑えることが可能です。
モデルの運用における経済面でのメリットのほか、ローカル環境での利用が可能となるため、医療機関やコンタクトセンタなど、SaaSを含むクラウド環境で機微情報を扱うことに障壁があるユースケースへの活用にも適しており、また推論速度の速さから高いレスポンス性能が必要なサービスへの活用が期待できます。
日本語と英語に対応 ~特に日本語が得意なLLM~
NTT研究所には40年以上に及ぶ自然言語処理研究の蓄積があり、AI分野の研究力は世界トップレベルです。AI分野論文数ランキング(2022年)*5では世界12位、国内1位となりました。また、自然言語処理分野のトップカンファレンスの論文採択数は国内企業1位であり、直近10年間の言語処理学会における優秀賞受賞件数も企業で1位と、長年実績をあげ続けています。
「tsuzumi」は日本語と英語に対応しており、特に日本語処理性能については、NTT研究所の長年の言語処理研究の蓄積を活かすことで、小さなパラメタサイズであっても各種のベンチマーク比較で高い精度が確認できています。生成AI向けのベンチマークであるRakuda*6、及び、Japanese Vicuna QA*7の性能比較結果を示します。どちらのベンチマークもGPT-4が2つのモデルの出力結果を優劣判定するもので、文書の構成や流暢さも含めて総合的に判定します。Rakudaベンチマークでは、GPT-3.5にも勝率52.5%と上回り、その他の国産トップのLLM群に対しては勝率70%超と大きく上回る結果となっています。Japanese Vicuna QAベンチマークは、コーディングや数学などRakudaベンチマークより幅広いカテゴリを含む評価セットです。こちらはGPT-3.5には勝率32.5%と及ばなかったものの、国産トップのLLM群に対して勝率55から80%超と大きく上回る結果となっています。(2023年10月NTT調べ)
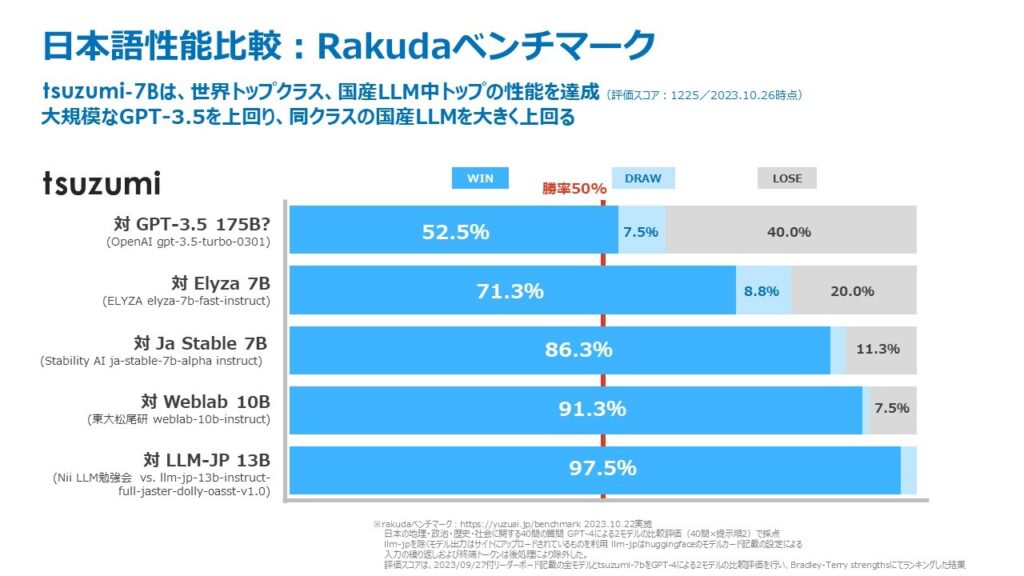
図4 Rakudaベンチマークでの比較(2023年10月 NTT調べ)
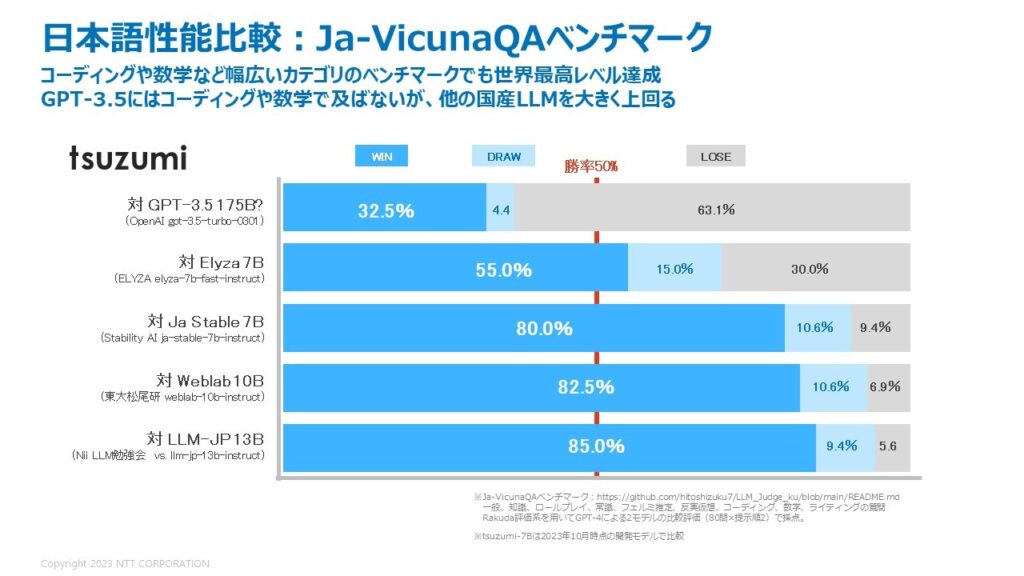
図5 Ja-VicunaQAベンチマークでの比較(2023年10月 NTT調べ)

図6 実際の言語モデルの回答比較とGPT-4の判定例
柔軟なチューニング ~基盤モデル+アダプタ~
LLMのチューニングは、モデルの振る舞いを特定のタスクや目的に合わせて調整するプロセスで、主な目的は、モデルが特定のタスクでより正確かつ有用な応答を生成することです。一般的には、タスクの適合性向上、ユーザや法的要件に従った制約の追加、特定ドメインや業界に特化した知識や語彙の獲得、応答のスタイルやトーン等の文体調整などにより、より望ましい応答を得ることが期待されます。
LLMに新しい知識を追加で学習させるようとする場合、膨大な数のパラメタ全てを再学習させると、計算にかかる学習コストが大きくなってしまいます。「tsuzumi」は、効率的に知識を学習させることのできるアダプタ*8により、例えば特定の業界に特有の言語表現や知識に対応するようなチューニングを少ない追加学習量で実現できます。
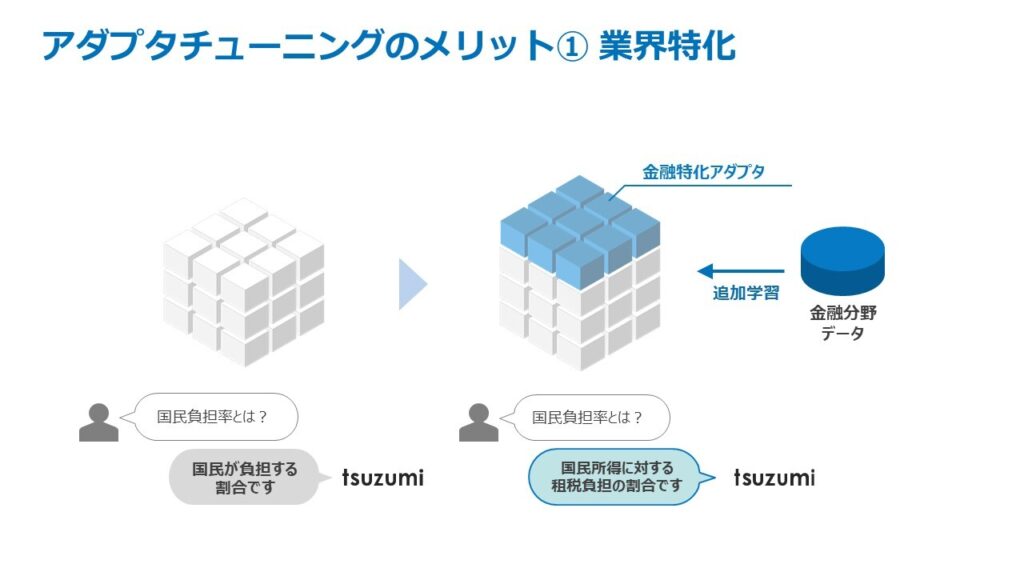
図7-1, 7-2 アダプタチューニングのメリット
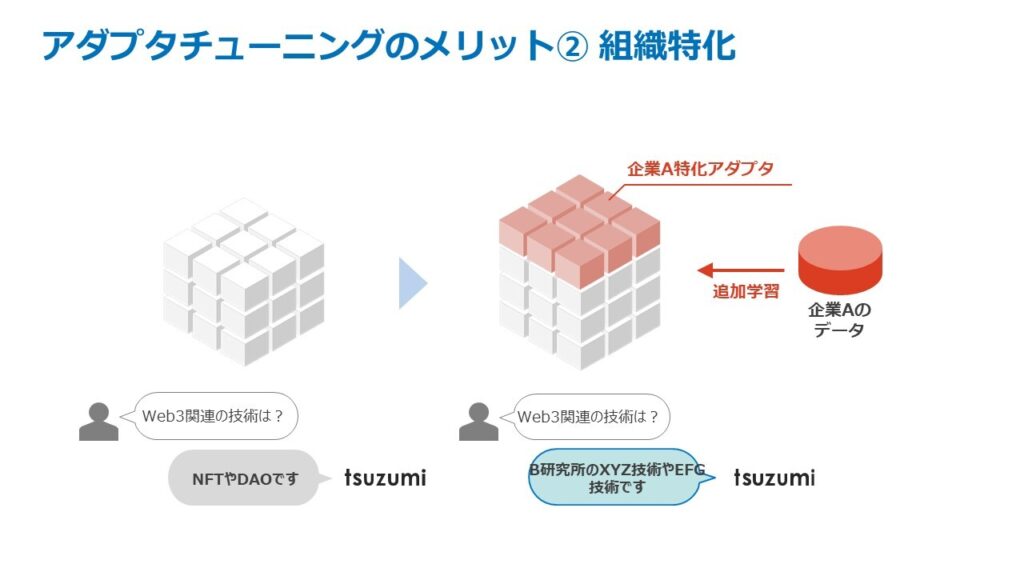
2024年4月以降は、利用ユーザやシーンに応じて複数のアダプタを柔軟に切り替えたり、組み合わせて相乗効果を生み出したりすることができる「マルチアダプタ」の機能を導入予定です。この機能では、一つの「tsuzumi」本体に複数のアダプタを接続することで、一つの計算機プロセスで複数のチューニングの対象に応じた処理をすることができ、サービスの提供コストを抑えることができます。これによって、例えば、企業の中でも特定の組織や役職・権限に応じたきめ細やかなチューニングを低コストで提供することができます。
また、「マルチアダプタ」の機能は、一つの「tsuzumi」本体に複数のアダプタを接続して用いることで、一つの計算機プロセスで複数のチューニングの対象に応じた処理をすることができ、サービスの提供コストを抑えることができます。
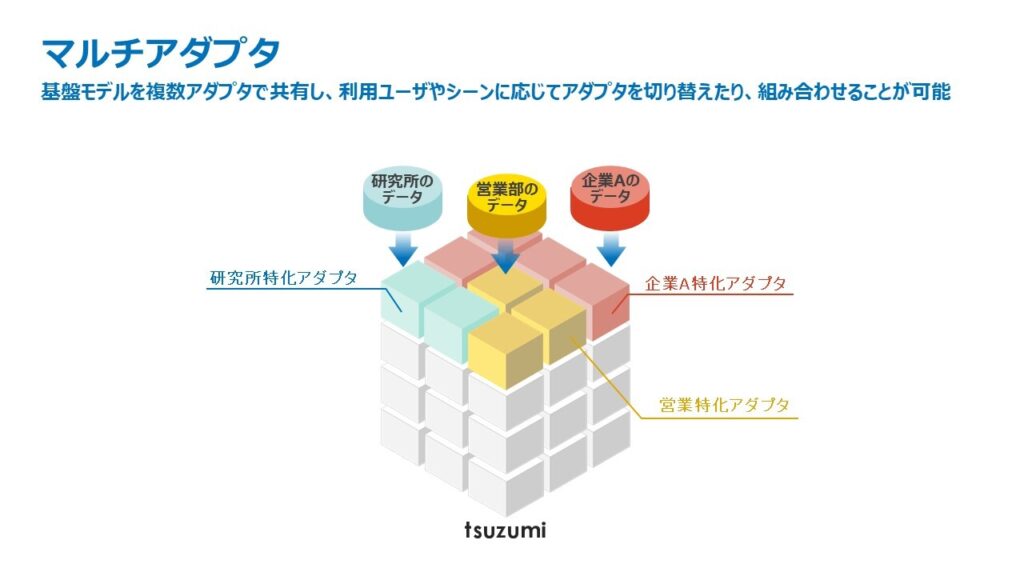
図8 マルチアダプタの実現イメージ
マルチモーダル ~言語+視覚・聴覚・ユーザ状況理解~
「tsuzumi」は必ずしも言語化されていないグラフィカルな表示や音声のニュアンス、顔の表情、ユーザのおかれている状況や、さらにはロボットが自分の身体感覚やヒトの身体的特徴を理解し、現実世界での人との協調作業も可能なモーダル拡張に対応予定です。(2024年3月以降)
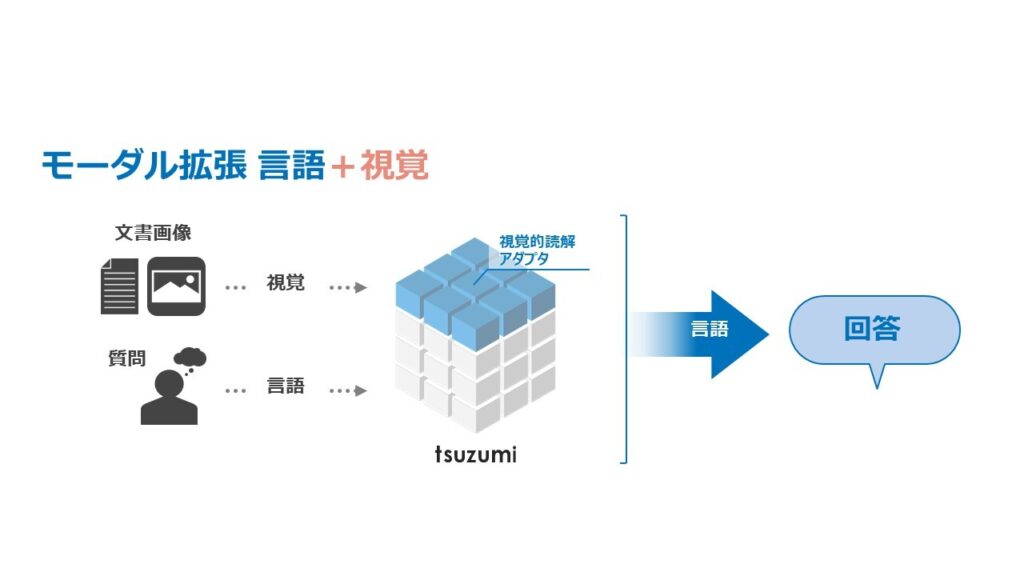
図9 言語+視覚のモーダル拡張
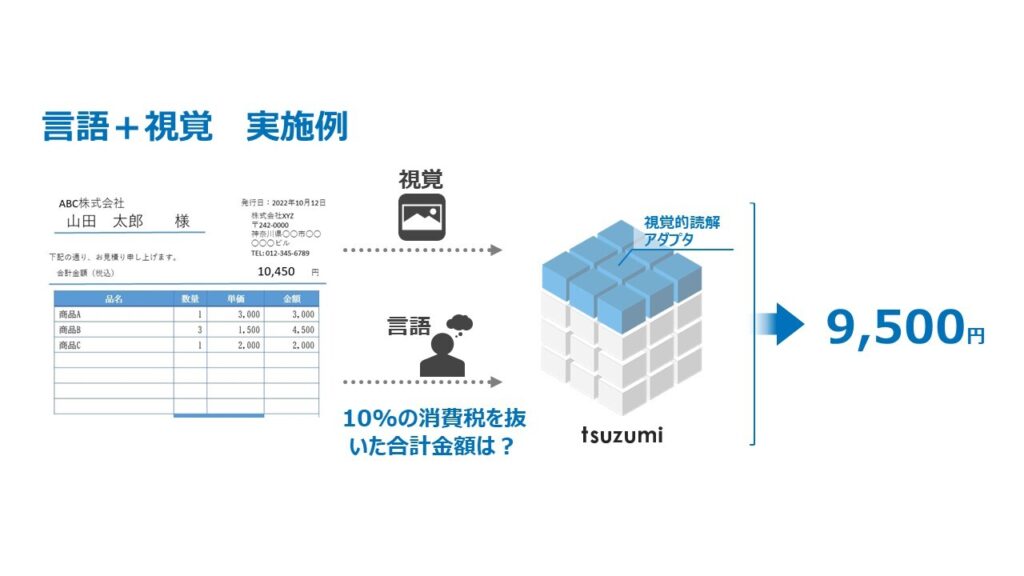
言語+視覚のモーダル拡張により、言語による質問だけでなく、文書画像を提示しながらの質問への回答が可能になります。例えば請求書やマニュアルなどの画像付き文書を検索・スクリーニングする業務や、ホームページに掲載されている商品説明や料金プラン説明をAIで比較評価する場合など、ビジネス上の多くの局面で必要とされるヒトの認知が必要な業務に言語モデルを活用することが可能です。またWeb 検索やチャットボットなど産業上重要なサービスの発展にも貢献が期待できます。
また図10-1はグラフィカルな文書を読み解く視覚的読解技術の実施例です。ここで「ブランド広告よりもオンラインレビューを信用しない人の割合は?」という質問に対しては、ポスターにある図表の円グラフの意味を正しく理解し、黒い部分の割合を回答する必要があります。「tsuzumi」では、このような図表の高度な理解を伴う質問に対しても正しい回答「30%」を導くような視覚読解技術の実現を目指しています。NTTは視覚的読解に2020年から取り組んでおり、最難関国際会議への複数件の論文採択や、国際コンペティションにおける上位入賞を果たしております。今後は「tsuzumi」をベースとした技術の確立を推進していきます。
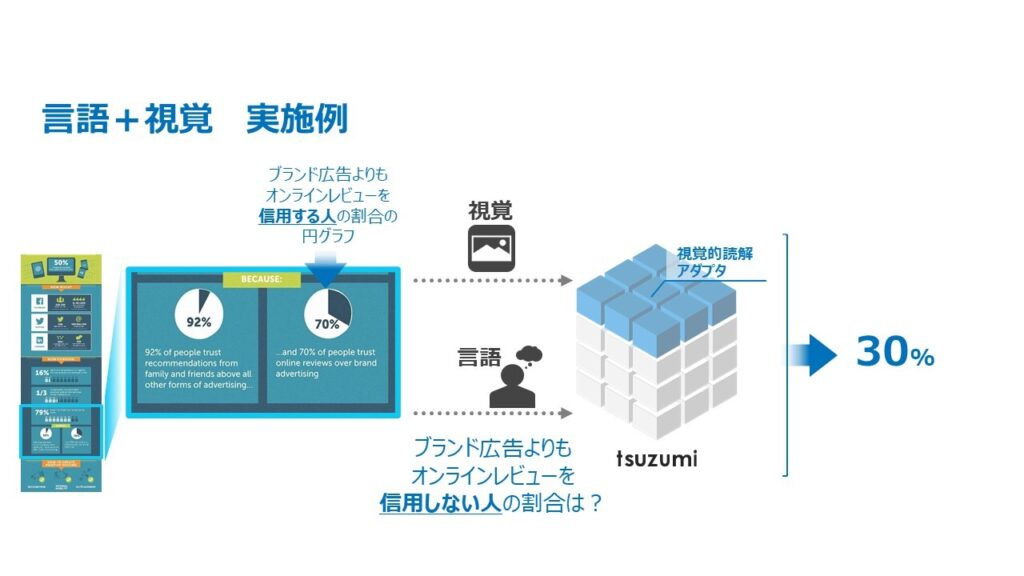
図10-1, 10-2, 言語+視覚モーダル拡張(実施例)
さらに、言語+視覚+聴覚のモーダル拡張により、言語による質問に加え、質問者の様子を踏まえた回答を生成可能になります。通常の音声認識では音声をテキストに変換することで、音声に含まれるニュアンスの情報が失われます。音声から感情の認識を行う場合でも、あらかじめ決められたいくつかの感情種別への分類を行うのが一般的です。これに対して、マルチモーダルに対応した「tsuzumi」を用いると、例えば子どもが元気のない声で話しかけると、「元気のない」「沈んだ」のような感情種別を内部で用いることなく、子どもの「元気のない状況」をそのまま理解し、これに応じて温かみのある優しい声で励ましの声をかけてくれるような動作を実現できるようになります。このような「tsuzumi」の特長は、カウンセリングやコールセンタなど、利用者の様々な状況に応じた自動応答への活用が期待できます。
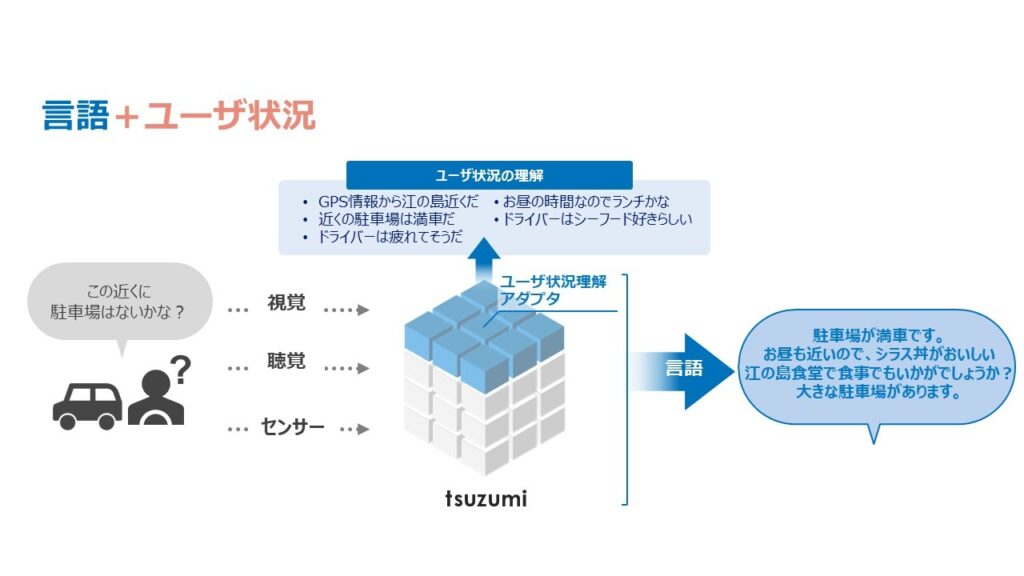
また、聴覚だけでなくユーザ状況(位置情報、駐車場の混雑状況、ドライバーの疲労度、時間帯、ユーザの好み情報等)を入力とすることで、カーナビ、スマホナビなどのコンシェルジュ業務への適用も可能です。
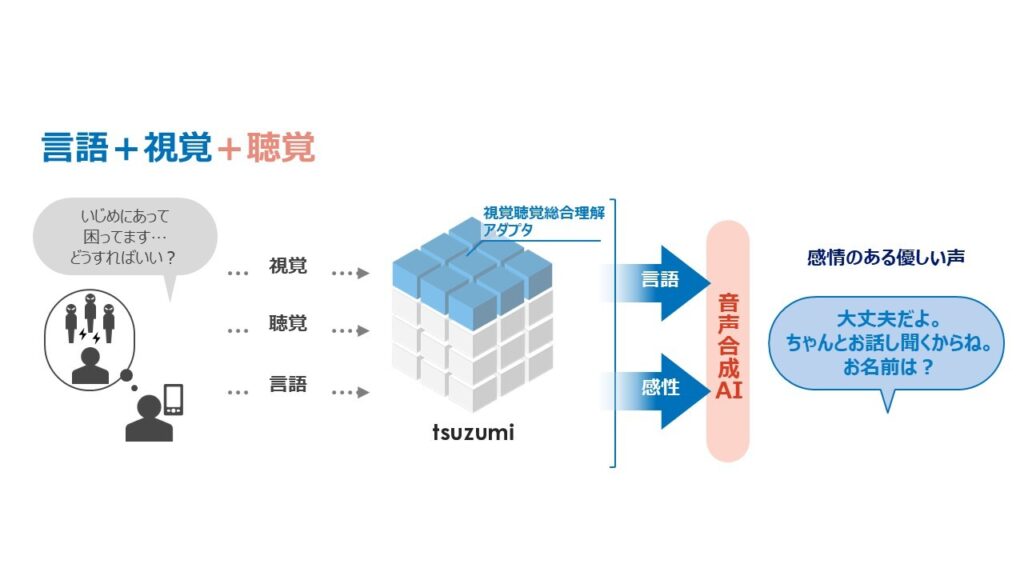
図11-1, 11-2 様々なモーダル拡張
おわりに
本稿では2023年10月時点でのNTT版大規模言語モデル「tsuzumi」の概要について解説しました。NTT研究所では長年の言語処理研究の蓄積を活かした技術の実用化を推進するとともに、さらなるLLMの研究開発領域として、サイバーセキュリティ分野への応用、自律的に連携し議論するAIコンステレーション等の研究開発にも取り組みます。
関連資料等
2023年11月1日 記者会見プレゼンテーション資料[3.24MB]
用語解説
*1 大規模言語モデル(LLM)
Large Language Models:大量のテキストデータを使って学習された言語モデルで、言語の理解や文章の生成に優れた能力をもつもの。
*2 tsuzumi
「tsuzumi」は商標出願中です。日本語の処理性能を重視し、産業の発展を牽引する言語モデル技術への期待を、雅楽の合奏の開始の切っ掛けを担う鼓に寄せました。
*3 マルチモーダル
AIへの入力情報の種類(テキスト、画像、音声など)をモーダルと言い、これらの異なる入力情報を組み合わせて使う能力をもった人工知能の特性を指す言葉。
*4 原発1基1時間分の電力量
パラメタ数が175BのGPT-3規模の学習に約1300MWhであり(1)、原発1基1時間分の電力量(約1000MWh)と同規模
(1) https://gizmodo.com/chatgpt-ai-openai-carbon-emissions-stanford-report-1850288635
*5 AI分野論文数ランキング
Top 100Global Companies Leading in AI Research in 2022
URL:https://thundermark.medium.com/ai-research-rankings-2022-sputnik-moment-for-china-64b693386a4
*6 Rakudaベンチマーク
日本語の言語モデルの性能を評価するベンチマークの一つで、日本の地理・政治・歴史・社会に関する質問応答タスクによって評価を行う。
URL:https://yuzuai.jp/benchmark
*7 Japanese Vicuna QAベンチマーク
Rakudaよりもさらに幅広いカテゴリで言語モデルのQAや指示遂行の能力を問う評価方法。一般知識、ロールプレイなど多数の質問から構成される。
URL:https://github.com/hitoshizuku7/LLM_Judge_ku/blob/main/README.md
*8 アダプタチューニング
事前学習済みモデルの外部に追加されるサブモジュール。ファインチューニングの際に事前学習済みモデルのパラメタを固定したままアダプタのパラメタのみを更新することで、計算コストの高いベースモデルの再学習を行わずに知識を学習することができる。
引用