本日、Amazon Bedrockが一般提供を開始したことをお知らせします。また、MetaのLlama 2 13B および 70B パラメータのモデルが、近日中に Amazon Bedrock で利用可能になることもお伝えします。
今年の4月、AWS で生成系 AI を構築するための新しいツールセットの一部として Amazon Bedrock を発表しました。Amazon Bedrockは、AI21 Labs、Anthropic、Cohere、Stability AI、Amazon などの先進的な AI 企業の高性能な基盤モデル (Foundation Models) を選択できるフルマネージドサービスです。プライバシーとセキュリティを維持しながら、生成系 AI アプリケーションの開発を簡素化する幅広い機能群を提供します。

Amazon Bedrockの包括的な機能により、さまざまなトップレベルの基盤モデルをサーバーレスで試すことができ、ファインチューニングや検索拡張生成 (Retrieval-Augmented Generation; RAG) などの技術を用いて、プライベートな環境で独自のデータを活用して基盤モデルをカスタマイズし、コードを書くことなく複雑な業務タスクを遂行するマネージドなエージェントを作成できます。 以前の投稿をチェックして、これらの技術を利用するための Agents for Amazon Bedrock や Knowledge Base についてさらに学ぶことができます。Agents for Amazon Bedrock や Knowledge Base を含む一部の機能は、引き続きプレビューでのみ利用可能であることに注意してください。このブログ記事の後半で、どの機能がプレビューで利用できるか詳細を共有します。
Amazon Bedrock はサーバレスなので、インフラを管理する必要がなく、すでに使い慣れている AWS サービスと連携して生成系 AI の機能をセキュアに統合およびデプロイできます。
Amazon Bedrock は Amazon CloudWatch および AWS CloudTrail と統合されており、モニタリングとガバナンスのニーズに対応しています。CloudWatch を使用して使用状況に関するメトリクスを追跡し、監査目的で独自のダッシュボードを構築できます。CloudTrail を使用すると、他のシステムを生成系 AI アプリケーションに統合する際に API 操作を監視し、トラブルシューティングをすることができます。 Amazon Bedrock を使用すると、GDPR に準拠したアプリケーションを構築でき、HIPAA(医療保険の相互運用性と説明責任に関する法律) で規制されるセンシティブなワークロードを実行できます。
Amazon Bedrock の利用を開始する
Amazon Bedrock で利用可能な基盤モデルは AWS マネジメントコンソールや、AWS SDK、LangChainなどのオープンソースフレームワークを通じてアクセスできます。
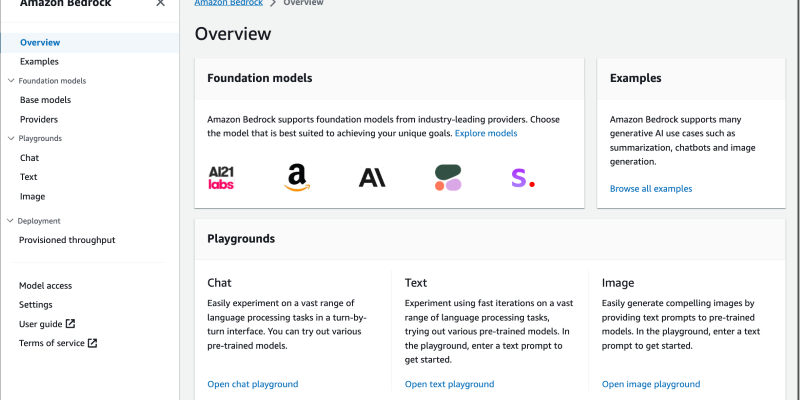
Amazon Bedrock のコンソールでは、基盤モデルを閲覧したり、各モデルの例となるユースケースやプロンプトを調べたり、読み込むことができます。はじめに、モデルへのアクセスを有効化する必要があります。コンソールで、左のナビゲーションペインの Model Access を選択し、アクセスしたいモデルの有効化を行いましょう。モデルアクセスが有効になると、さまざまなモデルを試し、ユースケースに適したモデルを見つけるために、さまざまな異なるモデルと推論に関する設定を試すことができます。モデルを試行する際には、本記事の最後に記載された料金モデルに従って支払いが発生します。
例えば、Cohere の Command モデルを使用した契約に関する固有表現抽出の例は以下のようになります:

この例では、プロンプト、サンプルのレスポンス、推論用パラメータの設定例、このサンプルを実行する API リクエストを示しています。Open in Playground を選択すると、インタラクティブなコンソールで、モデルとユースケースをさらに試すことできます。
Amazon Bedrockは、チャット、テキスト、画像の Playground を提供します。チャットの Playground では、会話型のチャットインターフェースを使用して、さまざまな基盤モデルを試すことができます。次の例では、Anthropic の Claude モデルを使用しています:

異なるモデルを評価する際には、様々なプロンプトエンジニアリングの手法や推論設定のパラメータを試すべきです。プロンプトエンジニアリングは、タスクやユースケースをよりよく理解し、基盤モデルを適用するための新しい技術です。効果的なプロンプトエンジニアリングとは、基盤モデルの能力を最大限に引き出し、適切かつ正確な返答を得るための完璧なクエリを作り上げることです。一般に、プロンプトはシンプルで直接的で、あいまいさを避けた方が良いです。プロンプトの中で例を提示したり、モデルに対してさらに複雑なタスクを推論させたりすることもできます。
推論設定のパラメータは、モデルが生成するレスポンスに影響します。Temperature、Top P、Top K などのパラメータは、ランダム性や多様性を制御し、Maximum Length や Max Tokens はモデルのレスポンスの長さを制御します。それぞれモデルは、互いに異なる推論パラメータをもっていますが、それらの中には重複するパラメータがあることに注意してください。これらのパラメータは、異なるモデルを試していくなかで、モデル間で同じ名前か、似たような名前であることに気づくでしょう。
AWSが DeepLearning.AI と共同開発した Generative AI with Large Language Models のオンデマンドコースの第1週目で、効果的なプロンプトエンジニアリング技術と推論設定のパラメータについて詳しく説明しています。Amazon Bedrock のドキュメントやモデルプロバイダーの関連ドキュメントを参照することで、追加のヒントを得ることができます。
次に、Amazon BedrockをAPI経由で操作する方法を見ていきましょう。
Amazon Bedrock API の利用
Amazon Bedrockは、ユースケースに合った基盤モデルを選択し、数回の API 呼び出しを行うだけの簡単な作業で利用することができます。以下のコード例では、Amazon Bedrock を操作するために、PythonのAWS SDK (Boto3) を使用します。
利用できる基盤モデルの一覧を取得
まず boto3 の Clientをセットアップし、list_foundation_models()を使って利用可能な最新の基盤モデルの一覧を取得しましょう。
import boto3
import json
bedrock = boto3.client(
service_name='bedrock',
region_name='us-east-1'
)
bedrock.list_foundation_models()Python
Amazon Bedrock の InvokeModel API を使って推論を実行
次に、Amazon BedrockのInvokeModel APIとboto3 ランタイムクライアントを使用して推論リクエストを実行しましょう。ランタイムクライアントは、InvokeModel APIを含むデータプレーン API を管理します。

InvokeModel API 次のパラメータを必要とします。
{
"modelId": <MODEL_ID>,
"contentType": "application/json",
"accept": "application/json",
"body": <BODY>
}modelIdパラメーターは使用する基盤モデルを指定します。リクエストの body は、タスクのプロンプトと、推論設定のパラメーターを含む JSON の文字列です。プロンプトのフォーマットは、選択したモデルプロバイダと基盤モデルによって異なります。contentType パラメーターと accept パラメーターは、リクエストの body とレスポンスのデータの MIME タイプを定義し、デフォルトは application/json です。最新のモデル、InvokeModel API のパラメーター、プロンプトのフォーマットに関する詳細は Amazon Bedrock のドキュメントを参照してください。
例: AI21 LabのJurassic-2 モデルを使用したテキスト生成
ここでは、AI21 Lab の Jurassic-2 Ultra モデルを使用したテキスト生成の例を示します。ノックノックジョークを話してとモデルにリクエストする、Hello Worldのようなものを試してみます。
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)
modelId = 'ai21.j2-ultra-v1'
accept = 'application/json'
contentType = 'application/json'
body = json.dumps(
{"prompt": "Knock, knock!",
"maxTokens": 200,
"temperature": 0.7,
"topP": 1,
}
)
response = bedrock_runtime.invoke_model(
body=body,
modelId=modelId,
accept=accept,
contentType=contentType
)
response_body = json.loads(response.get('body').read())Python
レスポンスは以下の通りです。
outputText = response_body.get('completions')[0].get('data').get('text')
print(outputText)
Who's there?
Boo!
Boo who?
Don't cry, it's just a joke!InvokeModel API を利用して Embedding (埋め込み) のモデルを利用することもできます。
例: Amazon Titan Embeddings Model を使用したテキスト埋め込みの作成
テキスト埋め込みモデルは、単語、フレーズ、あるいはもっと大きな単位のテキストなどを、埋め込みベクトルと呼ばれる数値表現に変換します。埋め込みベクトルは、テキストの意味的な内容を高次元のベクトル空間に符号化したもので、パーソナライゼーションや検索などのアプリケーションにおいて有用です。この例では、Amazon Titan Embeddings Model を使用して埋め込みベクトルを作成しています。
prompt = "Knock-knock jokes are hilarious."
body = json.dumps({
"inputText": prompt,
})
model_id = 'amazon.titan-embed-g1-text-02'
accept = 'application/json'
content_type = 'application/json'
response = bedrock_runtime.invoke_model(
body=body,
modelId=model_id,
accept=accept,
contentType=content_type
)
response_body = json.loads(response['body'].read())
embedding = response_body.get('embedding')Python
埋め込みベクトル (一部省略) は、例えば以下のようになります。
[0.82421875, -0.6953125, -0.115722656, 0.87890625, 0.05883789, -0.020385742, 0.32421875, -0.00078201294, -0.40234375, 0.44140625, ...]
Amazon Titan Embeddings は一般利用可能です。テキスト生成のための Amazon Titan Text モデルは、限定プレビューで引き続き利用可能です。
Amazon BedrockのInvokeModelWithResponseStream APIを使用して推論を実行するInvokeModel APIリクエストは同期的で、モデルが出力全体を生成するのを待つ必要があります。ストリーミングレスポンスをサポートするモデルの場合、入力した内容に対して、指定したモデルで推論を実行させながら、モデルが出力を生成するたびにレスポンスをストリーム形式で出力する InvokeModelWithResponseStream API を提供します。

ストリーミング形式のレスポンスは、インタラクティブなアプリケーションにおいて、ユーザを引きつけるような、反応の良いチャットインターフェースを提供する際に役立ちます。以下は、Amazon Bedrock のInvokeModelWithResponseStream APIを使用した Python コードの例です:
response = bedrock_runtime.invoke_model_with_response_stream(
modelId=modelId,
body=body)
stream = response.get('body')
if stream:
for event in stream:
chunk=event.get('chunk')
if chunk:
print(json.loads(chunk.get('bytes').decode))Python
データプライバシーとネットワークセキュリティ
Amazon Bedrock では、お客様がデータを完全にコントロールでき、入力した内容やカスタマイズした内容はお客様のAWSアカウント内でのみプライベートに保持されます。プロンプト、コンプリーション (出力)、ファインチューニングしたモデルなどのデータは、サービス改善のために使用されることはありません。また、データはサードパーティのモデルプロバイダーと共有されることもありません。
お客様のデータは、API コールが処理されたリージョン内にとどまります。すべての通信データ (in transit) は最低 TLS 1.2 で暗号化されています。保管データ (at rest) は、AWS KMS のマネージドデータ暗号化キーを使用したAES-256で暗号化されています。また、お客様自身のキー (カスタマーマネージドキー) を使用してデータを暗号化することも可能です。
お客様のAWSアカウントとVirtual Private Cloud (VPC) を設定することで、Amazon VPCエンドポイント (AWS PrivateLink を利用)を使用して、VPC内で実行されているアプリケーションとAmazon Bedrockの間を、AWSネットワーク上で安全に接続できます。これにより、アプリケーションとAmazon Bedrockの間で、セキュアでプライベートな接続が実現します。
ガバナンスとモニタリング
Amazon Bedrock は IAM と統合することで、Amazon Bedrock へのアクセス権限の管理を支援します。これらのアクセス権限には、特定のモデル、Playground、Amazon Bedrock 内の機能へのアクセスが含まれます。すべての AWS マネージドサービスの API 操作(Amazon Bedrock 操作を含む)は、お客様のアカウント内の CloudTrail に記録されます。
Amazon Bedrock は、AWS/Bedrock の名前空間を使用して InputTokenCount、OutputTokenCount、InvocationLatency、Invocations (呼び出し回数) などの一般的なメトリクス情報を CloudWatch に送信します。メトリクスを検索するときにモデル ID のディメンションを指定することで、結果をフィルタリングし、特定のモデルの統計を取得できます。このニアリアルタイムのインサイトにより、Amazon Bedrock で生成系 AI アプリケーションの構築を開始したときの使用量とコスト(入力および出力のトークン数)を追跡し、パフォーマンスの問題 (実行時のレイテンシと実行回数) をトラブルシューティングすることができます。
請求と料金モデル
請求と料金モデルに関して、Amazon Bedrockを利用する際には、以下を念頭に置いてください:
請求 – テキスト生成モデルは、処理された入力トークンと生成された出力トークンの両方について請求されます。テキスト埋め込みモデルは、処理された入力トークンについて請求されます。画像生成モデルは、生成された画像について請求されます。
料金モデル – Amazon Bedrockは、オンデマンドとプロビジョンドスループットの2つの価格設定モデルを提供しています。オンデマンド価格設定では、期間のコミットメントをすることなく、利用した分だけの支払いで基盤モデルを利用できます。プロビジョンドスループットは、主に大規模で一貫した推論ワークロード向けで、期間のコミットメントと引き換えに、保証されたスループットが必要な場合に設計されています。アプリケーションのパフォーマンス要件として、1分あたりの最大入力トークン数と出力トークン数を満たすために、特定の基盤モデルのモデルユニット数を指定します。詳細な価格情報は、Amazon Bedrockの料金をご参照ください。
Now Available
Amazon Bedrockは、現在AWSリージョンの US East (バージニア北部)とUS West (オレゴン) で利用できます。詳細は、Amazon Bedrock ウェブサイト、Amazon Bedrock のドキュメント、community.aws の generative AI のスペースをご覧ください。また、Amazon Bedrock workshopでハンズオン体験ができます。Amazon Bedrock に関するフィードバックは、AWS re:Post for Amazon Bedrockか、通常のAWSのお問い合わせ先までお送りください。
(プレビュー) Amazon Titan Textのテキスト生成モデル、Stability AI の Stable Diffusion XL 画像生成モデル、および agents for Amazon Bedrock (Knowledge Baseを含む) は、限定プレビューとして引き続き利用できます。アクセスをご希望の方は、AWSのお問い合わせ先までご連絡ください。
(近日公開) Meta の Llama 2 13Bおよび70Bパラメータモデルが、Amazon BedrockのフルマネージドAPIを通じて、推論とファインチューニングを利用できるようになります。
今日から Amazon Bedrock を利用して生成系 AI アプリケーションを構築しましょう!
引用