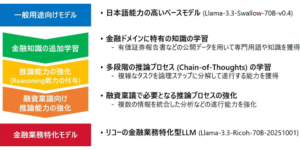
- Stable Audio Open は、最大47秒のサンプルとサウンドエフェクトを生成するための、オープンソースのテキストからオーディオへのモデルです。
- ドラムビート、楽器リフ、アンビエントサウンド、フォーリー、音響制作に必要な要素を作成できます。
- このモデルは、オーディオ・バリエーションとオーディオ・サンプルのスタイル転送を可能にします。
テキストプロンプトを使って短いオーディオサンプル、サウンドエフェクト、音響制作に必要な要素を生成するために最適化されたオープンソースモデル、Stable Audio Open をご紹介します。このリリースは、サウンドデザイナー、ミュージシャン、クリエイティブ・コミュニティの皆様の想像力を最大化させるために、ジェネレーティブ・オーディオ機能の一部をさらにオープン化する 重要なマイルストーンとなります。
Stable Audio Open とは
Stable Audio Openは、誰でも簡単なテキストプロンプトから、最長47秒の高品質オーディオデータを生成することができます。
専門的なトレーニングにより、ドラムビート、楽器リフ、アンビエントサウンド、フォーリー、その他ミュージックプロダクションやサウンドデザイン用のオーディオサンプルの作成に最適です。
このオープンソースリリースの主な利点は、ユーザーが独自のカスタムオーディオデータでモデルを微調整できることです。例えば、ドラマーは自分のドラム録音のサンプルを微調整して、新しいビートを生成することができます。
Stable Audio との違いは?
Stability AI の商用製品 Stable Audio は、3分までの首尾一貫した音楽構造を持つ高品質なフルトラックを作成し、オーディオからオーディオへの生成や首尾一貫したマルチパート作曲などの高度な機能も備えています。
一方、Stable Audio Open は、オーディオサンプル、サウンドエフェクト、音響制作に必要な要素に特化しています。短い音楽クリップを生成することはできますが、フルソング、メロディー、ボーカルには最適化されていません。このオープンなモデルは、クリエイティブなコミュニティとともに責任ある開発を優先しながら、サウンドデザインのための生成AIを垣間見せてくれます。
新しいモデルは、FreeSoundとFree Music Archiveのオーディオデータでトレーニングされました。これにより、クリエイターの権利を尊重しながら、オープンなオーディオモデルを作成することができました。
はじめましょう
Stable Audio Open モデルのウェイトは、Hugging Face で入手可能です。私たちは、サウンドデザイナー、ミュージシャン、開発者、オーディオ愛好家がモデルをダウンロードし、その機能を探求し、フィードバックをいただけることを楽しみにしています。
とても素晴らしい1歩ではありますが、これはまだオープンで責任あるオーディオ生成機能の始まりにすぎません。私たちは、創造的なコミュニティと協力しながら研究を続け、開発していくことを楽しみにしています。
引用