ポイント
- StableLM Zephyr 3B は、7B モデルより60%小さい30億パラメータの大規模言語モデル(LLM)であり、ハイエンドのハードウェアを必要とせず、様々なデバイス上で正確で応答性の高い出力を可能にします。
- モデルのウエイトとコードのダウンロードはこちらから。
- このモデルのスピードを最適化する方法については、こちらをご覧ください。
- このモデルは、非商用利用を目的とした非商用ライセンスの下で公開されています。
StableLM Zephyr 3B のリリースをお知らせします。これは、軽量 LLM シリーズの最新版であり、インストラクション・フォローや Q&A タイプのタスク向けに調整された新しいチャットモデルです。このモデルは、既存の StableLM 3B-4e1t モデルを拡張したもので、HuggingFace の Zephyr 7B モデルにインスパイアされたものです。StableLM Zephyr の30億パラメータにより、このモデルは、単純なクエリからエッジデバイス上の複雑なインストラクションコンテキストまで、幅広いテキスト生成ニーズに効率よく対応します。
トレーニングインサイト
StableLM Zephyr 3B の開発は、テキスト生成で優れたパフォーマンスを発揮し、人間の嗜好に沿ったモデルを作成することに重点を置きました。Zephyr 7Bにヒントを得て、我々はその学習パイプラインを適応させました。最初のステップは、UltraChat、MetaMathQA、Evol Wizard Dataset、Capybara Dataset を含む複数の命令データセットでのスーパービジョン付きファインチューニングです。次に、私たちのモデルを、UltraFeedbackデータセットを利用したDPO(Direct Preference Optimization)アルゴリズムと整合させました。このデータセットはOpenBMB研究グループによるもので、64,000のプロンプトと対応するモデルのレスポンスから構成されています。最近リリースされた Zephyr-7B、Neural-Chat-7B、Tulu-2-DPO-70B などのモデルも、Direct Preference Optimization(DPO)を使用して成功しています。しかし、Stable Zephyr は、3Bパラメータという効率的なサイズを持つ、このタイプの最初のモデルの1つです。
モデル性能
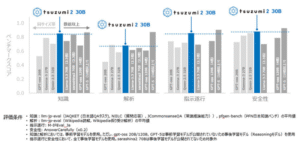
MT Bench や AlpacaEval などのプラットフォームでベンチマークを行った結果、StableLM Zephyr 3B は、文脈に即し、首尾一貫した、言語的に正確なテキストを生成する優れた能力を実証しました。
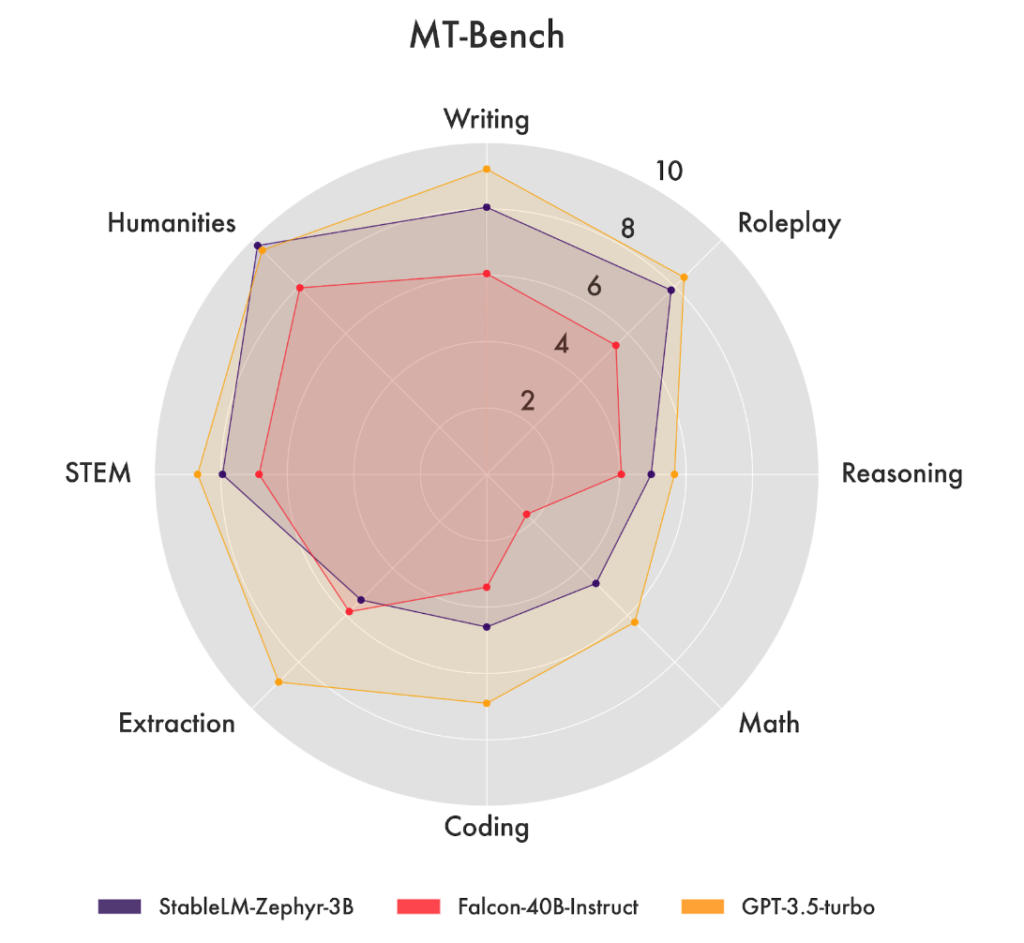
これらのテストにおいて、StableLM Zephyr 3Bの性能は、Falcon-4b-Instruct、WizardLM-13B-v1、Llama-2-70b-chat、Claude-V1など、いくつかの大きなサイズのモデルと競合することがわかりました。
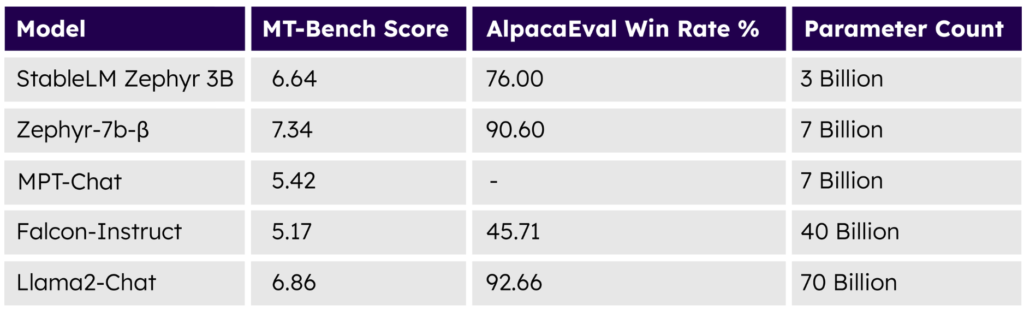
テスト、データセット、安全性についての詳細は、モデルカードをご覧ください。まとめると、性能テストでは、StableLM Zephyr 3B は、同様のユースケース向けに調整されたより大きなサイズのモデルを凌駕する能力があり、この新しいモデル固有のパワーと効率性を示しています。
多様なアプリケーションを可能に
StableLM Zephyr 3Bは、複数の言語タスクを効率的かつ正確に処理できる軽量ながら高精度なモデルです。このモデルは、インストラクションタスクやQ&Aタイプのタスクを支援するために強化されており、また、クリエイティブなコンテンツの作成(コピーライティングや要約など)から、教育デザインの開発やコンテンツのパーソナライゼーションの支援に至るまで、幅広い複雑なアプリケーションに対応できるほどの汎用性を備えています。さらに、入力データに基づく強力で洞察に富んだ分析を提供します。このモデルは7B モデルより60%小さい30億パラメータという効率的なサイズを維持しており、ハイエンド専用システムのような計算能力を持たない機器でも使用することができます。
このモデルを業務用製品や用途に使用したい場合は、こちらからお問い合わせください。
引用