Geminiとは
Googleの大規模言語モデルGeminiとは、2023年12月に発表された、テキストや画像、音声、動画、コーディングなど、様々な分野の情報を同時に活用できる「マルチモーダル」なAIモデルです。
Google DeepMindによって開発されたGeminiには、Ultra、Pro、Nanoの3つのバージョンがあります。それぞれは異なる規模と用途に最適化されています。
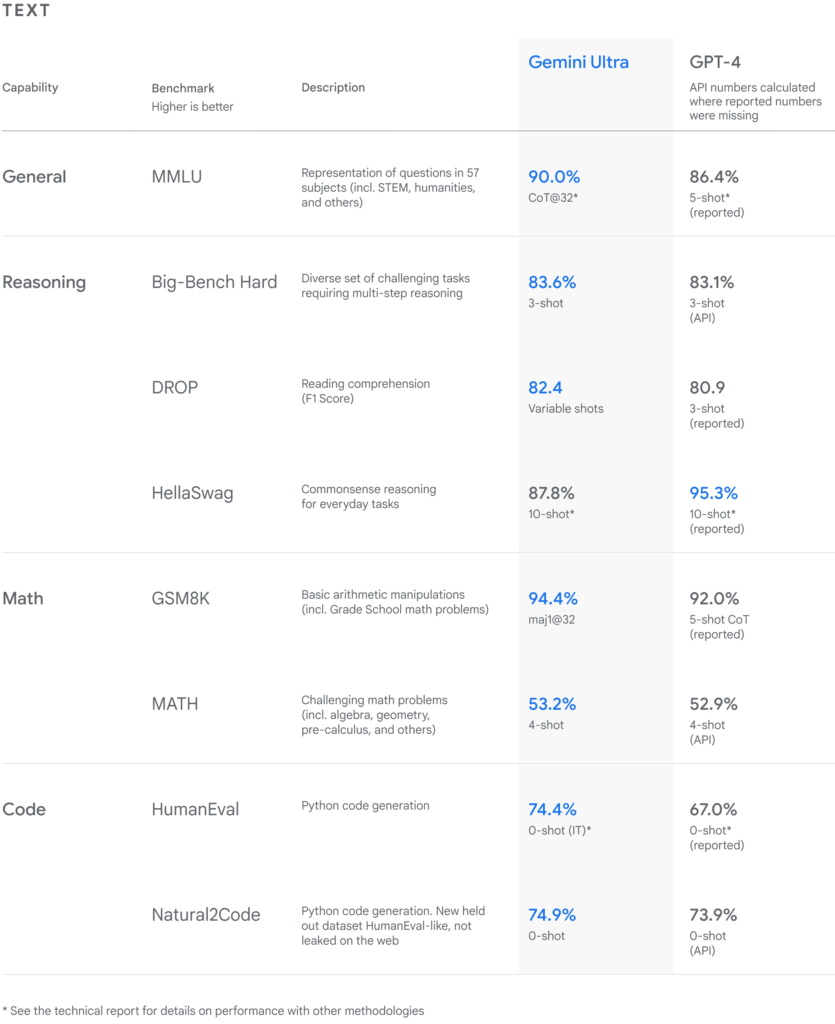
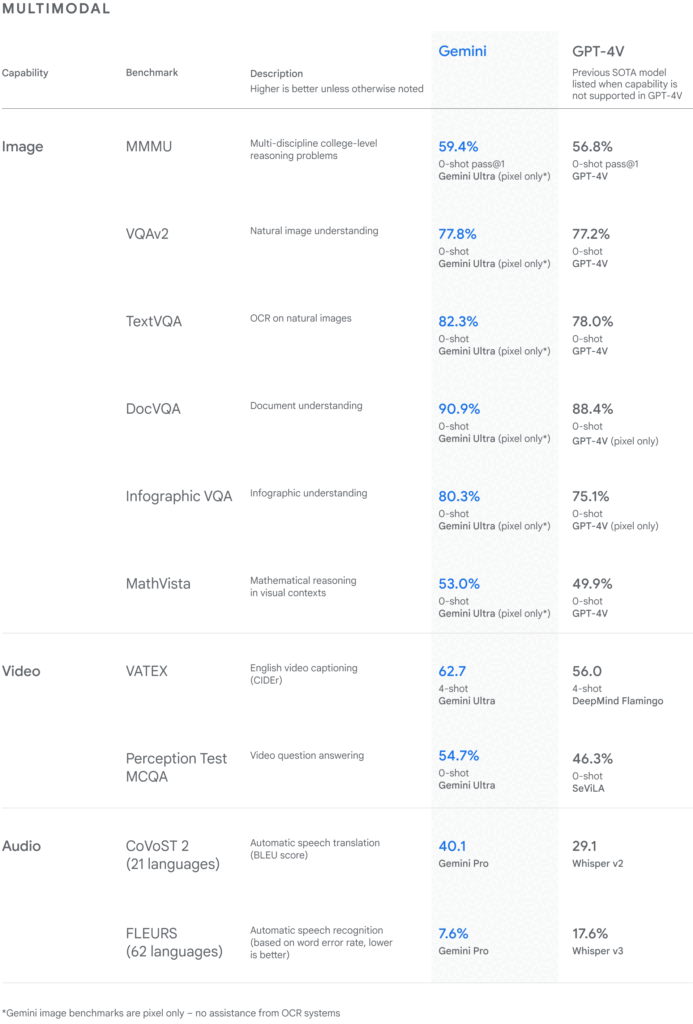
- Gemini Ultra は最も大規模なモデルで、非常に複雑なタスクに適しています。様々な学術ベンチマークで優れた性能を示し、Massive Multitask Language Understanding(MMLU)テストで人間の専門家を上回る90%のスコアを達成しました。このバージョンは、テキスト、コード、オーディオ、画像、ビデオを理解し、推論する能力を持っており、最先端のマルチモーダル能力を提供します。
- Gemini Pro は幅広いタスクに適しています。これは多様なAIアプリケーションで効率的かつ多用途に使用できるように設計されています。
- Gemini Nano は最も効率的なモデルで、特にスマートフォンのようなデバイス上でのタスクに適しています。これは、より大きなGeminiモデルから抽出されており、大規模なインフラストラクチャを必要とせずに効率的なAI処理を実現するアプリケーションに適しています。
Google Geminiの特徴として初めからマルチモーダルを前提に開発した、このモデルが初めからマルチモーダルを前提に設計されている点です。これは、従来のAIモデルとは一線を画すアプローチであり、AIの能力と応用範囲を大きく拡張しています。
特に最も大規模な言語モデルのGemini Ultraは32のベンチマークで、GPT-4とGPT-4Vを上回る結果を示したとしています。
Geminiでできること
Geminiはマルチモーダルな情報を処理できることによって、さまざまなタスクが行えます。
Googleが公開しているデモでは、「子供の宿題の手助け」をテーマに
- 手書きの答えが書かれたワークシートの写真から情報の読み取り
- 間違いの特定と詳細な説明
- 質問への解答と練習問題の提供
を行っています。
他にも、さまざまな画像や動画情報からの判別と解答を例にとした動画を公開をしています。
また、現在のGoogleBardに搭載されている大規模言語モデルのPalmと同等のタスクをより高度に行えると推測できます。

Geminiの利用方法
GoogleのGemini AIモデルは、さまざまなバリエーションで提供され、それぞれ異なる用途や機能を持っています。
主要なモデルであるGemini Ultra、Gemini Pro、Gemini Nanoの利用方法について説明します。
Gemini Ultra
来年には、Gemini Ultra で動作する、高性能モデルと機能にアクセスできる最先端の AI 体験を提供する Bard Advancedを提供予定。
Gemini Pro
Bard(英語版のみ)で提供を開始、さらに開発者向けに12月13日より、Google AI Studioまたは Vertex AIのGemini APIを介してGemini Proへのアクセスを提供。
Gemini Nano
Google Pixel 8 Proで利用可能、最初はレコーダーアプリの要約機能やGboardのスマートリプライなどで利用可能。
またAndroid開発者は、AICoreを介してGemini Nanoを利用し、モバイルアプリケーションの開発に活用できます。
また今後、Googleの検索、広告、Chrome、Duet AI などの Google の主要な製品やサービスで利用できるようになるとしています。
おわりに
生成AIに対するGoogleの本気が感じられた内容だと思いました。
今後GeminiやGoogleの動向、BardやAPIから使ってみた内容を記事にしていこうと思います。