※本ブログは、米国時間 4 月 23 日に公開された “Tiny but mighty: The Phi-3 small language models with big potential” の抄訳を基に掲載しています。
時に、複雑な問題を解決する最善の方法が子供向けの本を参考にすることであったりします。これは、マイクロソフトの研究者が、より小さなパッケージにより多くのパワーを詰め込む方法を見つけ出す特に学んだ教訓です。
昨年、マイクロソフトリサーチの機械学習専門家ローネン エルダン (Ronen Eldan) は、仕事で機械学習の謎に対する潜在的な解決策を考え抜いた後、娘の就寝前に本を読んであげていました。その時、「娘はどうやってこの言葉を学んだのだろう?」「どうやってこの単語のつなぎ方を学んだのだろう?」と自問しました。
これを契機に、エルダンは、4 歳児が理解できる言葉だけを使って、AI モデルがどれだけのことを学習できるのだろうかと考えるようになりました。これは、最終的には、AI をより多くの人々が利用できるようにする可能性を広げる、新たなカテゴリーの高性能小規模言語モデルを生み出す革新的な学習アプローチへとつながっていきました。
大規模言語モデル (LLM) は、AI を活用してより生産的かつ創造的になるための新しい機会を生み出しました。しかし、大規模であることは、その稼働に多大なコンピューティングリソースを必要とすることを意味します。
LLM が、多くの種類の複雑なタスクを解決するための最右翼であることに変わりはありませんが、マイクロソフトは、LLM の同等機能の多くを提供しながら、サイズが小さく、より少量のデータで訓練できる小規模言語モデル (SLM) を開発してきました。
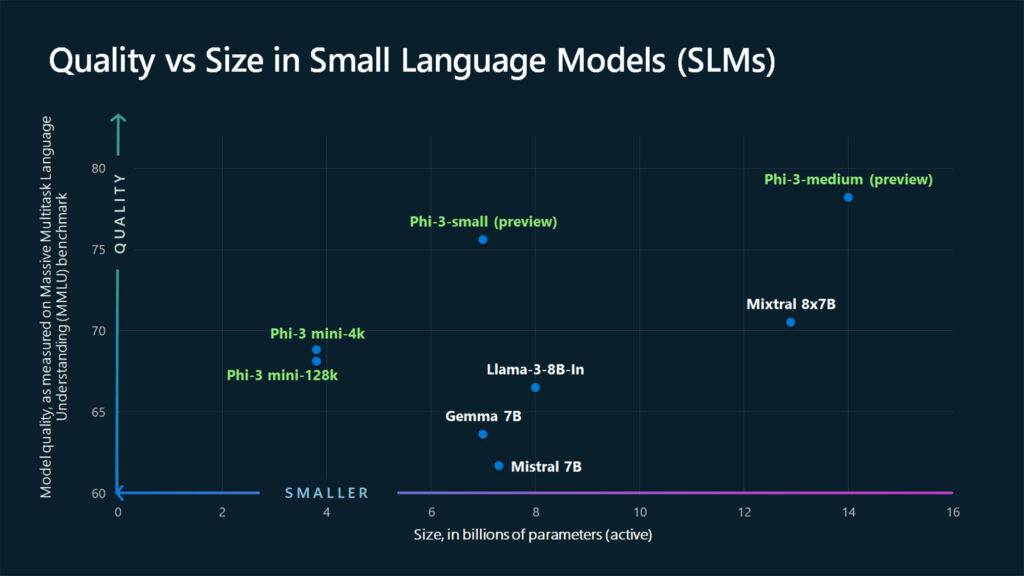
本日、マイクロソフトは、最も高性能でコスト効率の高い小型言語モデルである Phi-3 ファミリーのオープンモデルを発表しました。マイクロソフトの研究者によって開発された学習のイノベーションにより、Phi-3 モデルは、言語、コーディング、数学の能力を評価するさまざまなベンチマークにおいて、同等やそれ以上のサイズのモデルを上回っています。
現在、マイクロソフトは強力な一連の小規模言語モデルの第一弾として Phi-3-mini を公開しています。Phi-3-mini は、38 億個のパラメータを持ち、同社によれば、2 倍のサイズのモデルよりも優れた性能を発揮します。
Phi-3-mini は、本日より、Microsoft Azure AI Model Catalog で提供され、機械学習モデルのプラットフォーム Hugging Face、および、ローカルマシン上でモデルを実行するための軽量フレームワークである Ollama で利用できるようになります。さらに、NVIDIA NIM マイクロサービスとしても利用可能になり、通常の API インターフェースでどこでもデプロイすることができます。
また、マイクロソフトは、Phi-3 ファミリーの追加モデルを近日中に発表し、品質とコストの両面でより多くの選択肢を提供していく予定です。Phi-3-small (70億パラメータ) と Phi-3-medium (140億パラメータ) が、Azure AI Model Catalog などのモデル運用基盤でまもなく利用可能になります。
小規模言語モデルは、より単純なタスクに対して優れた性能を発揮するように設計されており、リソースが限られている組織にとっては、よりアクセスしやすく使いやすい存在です。
マイクロソフト 生成 AI 担当主任プロダクトマネージャー ソナリ ヤダヴ (Sonali Yadav) は、「今後見られるようになるのは、大規模から小規模へのシフトではなく、モデルの単一カテゴリーからモデルのポートフォリオへのシフトです。お客様は自分のシナリオに最適なモデルを決定できるようになるでしょう」と述べています。
マイクロソフト AI 担当バイスプレジデント ルイス ヴァルガス (Luis Vargas) は、「小さなモデルだけが必要なお客様も、大きなモデルが必要なお客様もいらっしゃいますが、多くのお客様はさまざまな方法で両方を組み合わせたいと考えるでしょう」と述べています。
適切な言語モデルの選択は、組織固有のニーズ、タスクの複雑度、利用可能なリソースに依存します。小規模言語モデルは、(クラウドではなく) デバイス上でローカルに実行でき、タスクが広範な推論を必要としない、あるいは、迅速な応答が必要なアプリケーションの構築を検討している組織に適しています。
「小さなモデルだけが必要なお客様も、大きなモデルが必要なお客様もいらっしゃいますが、多くのお客様はさまざまな方法で両方を組み合わせたいと考えるでしょう」
大規模言語モデルは、高度な推論、データ分析、コンテキストの理解を含む複雑なタスクの組み合わせが必要なアプリケーションに適しています。
小規模言語モデルは、高品質な結果が必要でありながら、データを自社内に保持したいことがある規制産業や部門にとっても、潜在的に有効なソリューションでもある、とヤダヴは述べています。
ヴァルガスとヤダヴは、クラウドに接続されていない「エッジ」で動作するスマートフォンなどのモバイル機器に、より高性能な SLM を搭載する機会に特に期待しています。(車載コンピューター、Wi-Fi のない PC、交通管理システム、工場フロアのスマートセンサー、監視カメラ、環境適合性を監視するデバイスなどを思い浮かべてください。) データをデバイス内に保持することで、ユーザーは「レイテンシを最小化し、プライバシーを最大化できる」とヴァルガスは述べています。
レイテンシとは、LLM がクラウドと通信し、ユーザーのプロンプトに対する回答を生成するための情報を取得する際に発生する遅延のことです。高品質な回答を待つ価値がある場合もあれば、ユーザー満足度のためにはスピードの方が重要な場合もあります。
SLM はオフラインで動作するため、これまでは不可能だった方法で AI を活用できる人が増えるであろうと、ヴァルガスは述べています。
たとえば、SLM は携帯電話サービスのない地域でも利用できます。農作物を検査する農家が、葉や枝に病気の兆候を見つけたとしましょう。視覚機能を備えた SLM を使えば、農家は問題のある作物の写真を撮って、害虫や病気の対処方法を即座に得ることができます。
「ネットワークが不充分な地域にいても、自身のデバイスで AI を活用できます」とヴァルガスは述べています。
高品質データの役割
その名の通り、SLM は、LLM に比べれば、少なくとも AI の基準からすれば小さなものです。Phi-3-mini のパラメータ数は「わずか」38 億個です。パラメータ数とはモデルの出力を決定するアルゴリズム上の調整ノブの数のことです。対照的に、大規模言語モデルのパラメータ数は何桁も上です。
大規模言語モデルによってもたらされた生成 AI の大きな進歩は、その巨大さによって可能になったと考えられてきました。しかし、マイクロソフトのチームは、小さなパッケージで大きな結果を出せる小規模言語モデルを開発することができました。この画期的な進歩を可能にしたのは、高度に選択的な学習データへのアプローチでした。ここに、子供向けの本の話が関係してきます。
これまで、大規模な言語モデルを訓練する標準的な方法は、インターネット上の大量のデータを使用することでした。このタイプのモデルが、言語のニュアンスを理解し、ユーザーのプロンプトに対して知的な回答を生成するための「学習」に必要なコンテンツに対する旺盛な欲求を満たすには、これが唯一の方法だと考えられていました。しかし、マイクロソフトの研究者は違う考えを持っていました。
「生のウェブデータだけで学習させるのではなく、きわめて質の高いデータを探してみてはどうでしょうか?」と、高性能な小規模言語モデルの開発を主導してきた、マイクロソフト 生成 AI リサーチ担当バイスプレジデント セバスチャン ブベック (Sebastien Bubeck) は尋ねます。しかし、どこにフォーカスすべきでしょうか?
マイクロソフトの研究者たちは、エルダンが毎晩娘と行っている読書の習慣にヒントを得て、名詞、動詞、形容詞をほぼ同数含む 3,000 語を元にした個別のデータセットを作成することにしました。次に、大規模言語モデルに、リストの中から名詞、動詞、形容詞を 1 つずつ使って童話を作ってもらいました。このプロンプトは数日間にわたって何百万回も繰り返され、何百万もの小さな童話が生まれました。
「SLM は、クラウドに行かなくてもできる計算のために独自のポジションを占めています」
彼らはこのデータセットを “TinyStories” (小さな物語) と名付け、約 1,000 万パラメータから成る非常に小規模な言語モデルの学習に使用しました。驚いたことに、TinyStories で学習させた小規模言語モデルは、独自のストーリーを作成するようプロンプトされると、完璧な文法で流暢な物語を生成したのです。
次に彼らは、ワンランク上の実験を行ないました。今度は、より多数の研究者グループが、教育的価値とコンテンツの質に基づいてフィルタリングされた一般公開データを使用して、Phi-1 を訓練しました。一般に公開されている情報を最初のデータセットとして収集した後、TinyStories で使用されたものにヒントを得たプロンプトとシーディングの方式を使用し、さらに一歩進んで、より幅広いデータを捕捉できるように高度化しました。高品質を保証するために、LLM に戻してさらに合成する前に、出来上がったコンテンツを繰り返しフィルターしました。こうして、数週間をかけ、より高性能な SLM を訓練するのに十分なサイズのデータコーパスを構築しました。
AI が生成したデータについてブベックは次のように述べています。「合成データの生成には多くの注意が払われています。精査し、意味があるものかどうかを確認し、フィルターしています。私たちは生成されたものをすべて受け入れるわけではありません。」このデータセットは “CodeTextbook” と呼ばれています。
研究者たちは、教師が生徒のために難しい概念を分解して解説するかのようにデータ選択にアプローチすることで、データセットをさらに強化しました。「教科書のような文章や、ものごとを適切に説明するきわめて高品質の文書を使用しているので、言語モデルの学習タスクははるかに容易になります」とブベックは述べています。
質の高い情報と低い情報を区別することは、人間にとっては難しいことではありません。しかし、マイクロソフトの研究者が SLM の訓練に必要と判断した 1 テラバイト以上のデータを整理することは、LLM の助けがなければ不可能です。
「合成データの生成という点で、現在の大規模言語モデルのパワーは、以前にはなかった強力な支援テクノロジです」と、この新たな学習のアプローチが開発された Microsoft Research AI Frontiers Lab を統率するバイスプレジデント、エチェ カマール (Ece Kamar) は述べています。
慎重に選択されたデータから開始することで、モデルが望ましくない回答や不適切な回答を返す可能性を減らすことができますが、すべての潜在的な安全性の課題を解決するには十分ではありません。他のすべての生成 AI モデルと同様に、マイクロソフトの製品チームと Responsible AI 担当チームは、Phi-3 モデルの開発におけるリスクの管理と軽減のために、多層的アプローチを採用しました。
たとえば、最初の学習の後、モデルがどのように反応するのが理想的かについて、追加の例やフィードバックを提供しました。これは、追加の安全層を構築し、モデルが高品質の結果を生成するのに役立ちます。また、各モデルは、専門家が潜在的な脆弱性を特定し、対処するための評価、テスト、レッドチーム演習の対象にもなります。
最後に、Phi-3 モデルファミリーを使用する開発者は、Azure AI で利用可能なツール群を活用し、より安全で信頼性の高いアプリケーションを構築することもできます。
タスクに適切なサイズの言語モデルの選択
しかし、高品質のデータで訓練された小規模言語モデルにも限界はあります。深い知識の探索には向いていないのです。これに対して、大規模言語モデルは、より大きな容量と、より大きなデータセットを使用した学習を行っている点で優れています。
LLM は、そのサイズと処理能力により、大量の情報が関係する複雑な推論において SLM よりも優れています。たとえば、膨大な科学論文の蓄積に目を通し、複雑なパターンを分析し、遺伝子、タンパク質、化学物質間の相互作用を理解する必要がある、創薬の領域ではこれが重要でしょう。
「そのタスクが十分に複雑で、そのタスクをどのようにサブタスク、場合によってはサブサブタスクに分割するかを考え、最終的な答えを出すためにそれらすべてを実行する必要がある ― そういった領域では、当面の間、大規模モデルが必要でしょう」とヴァルガスは述べます。
現在進行中の顧客との会話に基づき、ヴァルガスとヤダヴは、それほど複雑でない一部のタスクを小型モデルに「オフロード」する企業も出てくるだろうと予想しています。

たとえば、長い文書の要点を要約したり、市場調査レポートから関連するインサイトや業界動向を抽出するために、Phi-3 を使用できます。また、マーケティングチームや営業チームが商品説明やソーシャルメディアポストなどのコンテンツを作成するために Phi-3 を使用することもあるでしょう。あるいは、Phi-3 を使ってサポートチャットボットを構築し、顧客の商品に関する基本的な質問や、サービスのアップグレードについて回答することもできます。
マイクロソフトは、社内的に、すでにモデルのポートフォリオを使用しています。そこでは、大規模言語モデルがルーターの役割を果たし、コンピューティングパワーをあまり必要としない特定のクエリを小規模言語モデルに誘導する一方、その他の複雑なリクエストは大規模言語モデルが処理しています。
「ここで言いたいことは、SLM が大規模言語モデルに取って代わるということではありません。SLM はエッジ上での計算、デバイス上での計算、クラウドに行かなくてもできる計算のために独自のポジションを占めています。だからこそ、このポートフォリオ中の各モデルの長所と短所を理解することが重要なのです」とカマールは述べます。
そして、サイズには重要な利点があります。ブベックによれば、小規模言語モデルと、クラウド上の大規模モデルから得られるインテリジェンスのレベルにはまだギャップがあります。「そして、おそらくはこのギャップは常に存在していくことになるでしょう。大規模モデルも進歩し続けるからです。」
関連情報
- Introducing Phi-3, redefining what’s possible with SLMs (Phi-3 の紹介: SLM で可能になることを再定義)
- Azure AI
- Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone (Phi-3 テクニカルレポート: スマートフォンで使える高度言語モデル)
トップ画像: より高度な小規模言語モデルの開発を主導した、マイクロソフト 生成 AI リサーチ担当 バイスプレジデント セバスチャン ブベック (Photo by Dan DeLong for Microsoft)
—
本ページのすべての内容は、作成日時点でのものであり、予告なく変更される場合があります。正式な社内承認や各社との契約締結が必要な場合は、それまでは確定されるものではありません。また、様々な事由・背景により、一部または全部が変更、キャンセル、実現困難となる場合があります。予めご了承下さい。
引用