論理推論を可能とする大規模言語モデルの研究開発が「GENIAC」に採択
当社は、経済産業省が推進する国内の生成AIの開発力を強化するためのプロジェクト「GENIAC(Generative AI Accelerator Challenge)」のもと、国立研究開発法人新エネルギー・産業技術総合開発機構(以下、NEDO)が公募した、「ポスト5G情報通信システム基盤強化研究開発事業/ポスト5G情報通信システムの開発(助成)」に採択され(注1)、論理推論を可能とする大規模言語モデル(以下、LLM)の研究開発を開始します。
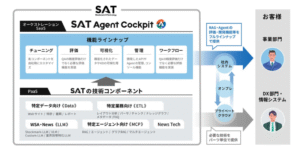
当社は、企業における生成AI活用の課題を解決する業務に特化した生成AIの提供を目指して研究開発を行っています。生成AIの業務活用における大きな課題の一つが、様々な業務のニーズに応じた性能と機能の提供が挙げられます。現行の汎用LLMでは計算量やコスト、精度などが業務要件を満たさない場合、業務特化型のLLMが有効です。当社は、「富岳」を用いて学習した日本語能力に優れた「Fugaku-LLM」の開発と提供を行っており(注2)、今後も様々な業種や業務に特化した特化型LLMの開発を強化していく予定です。
生成AIの業務活用の二つ目の大きな課題は、信頼性の担保です。自然言語処理に特化した生成AIの一種である現行のLLMは知識不足の事柄について根拠に基づかないもっともらしい誤りを回答してしまう幻覚(ハルシネーション)が発生することに加えて、LLMが内部パラメータとして保有している知識を把握する手段がないため、信頼性が求められる業務へのLLM導入が進まないことが課題でした。
そこで当社は、LLMに回答させる時に、必要な業務知識を自然言語ではなく知識処理技術の一つであるナレッジグラフの形式でLLMに追加入力すると、より業務知識に従って回答させられることに着目しました。LLMがさらに高度な推論をナレッジグラフに従って進められるようにするために、当社ではナレッジグラフとLLMを融合する新技術の開発に着手し、2024年度中の業務活用の実現を目指します。この新技術は、2023年9月に発表した当社の幻覚検出技術(注3)をさらに強化するものです。当社ではナレッジグラフに関して10年以上にわたる継続的な研究開発を行っており、ナレッジグラフの抽出から構築、検索、AI活用などに渡り多くの知見を有しています(注4 , 注5)。新技術は最終的に、人間が理解しやすい形式で根拠を説明しながら、業務知識に従って論理推論を進めるLLMを実現するもので、規制や規則への準拠と説明を要する法務分野での不法行為判定や根拠検索、金融分野における内部統制や会計監査、医療分野での症状検索や診断支援などの業務へのLLM適用が進むことが期待されます。
【当社が取り組む論理推論を可能にするLLMの開発について】
本助成事業では、知識処理技術の一つであるナレッジグラフの生成と推論に特化したLLMを開発することで、自然言語の規制や規則から生成したナレッジグラフに従ってLLMに回答を論理推論させる技術の実現を目指します。本技術は最終的に、当社が全社AI戦略(注6)として掲げ2024年度中の実現を目指す「出力の不安定性を解消し、条文が長く複雑な法規制や社内規則に準拠した正確な出力を保証する生成AIトラスト技術」の中核技術となります。
本助成事業では、「自然言語文書をナレッジグラフに変換して形式知にするLLM(ナレッジグラフ生成LLM)」と、「与えられた質問に対してナレッジグラフ上で関連情報を探索し、論理的に集約し回答するLLM(ナレッジグラフ推論LLM)」の二つの特化型LLMを開発します。限られた開発期間で二つの特化型LLMを効率よく開発するために、まず両特化型LLMに共通的な事前学習済みLLMを開発します。本LLM開発の特長は、自然言語文書とナレッジグラフの双方を同等に扱う能力をLLMに獲得させるために、自然言語文書とナレッジグラフとの対訳コーパス(注7)を事前学習データに追加する点です。その上で一方にはナレッジグラフ生成向けの指示学習(注8)を、もう一方にはナレッジグラフ推論向けの指示学習をそれぞれ実施することで、各特化型LLMを同時並行で開発します。
【今後について】
本助成事業の成果物である、ナレッジグラフの生成や推論に特化したLLMや、ナレッジグラフ生成や推論タスクの評価スクリプト、その他開発中に得た知見やノウハウなどは、利用したデータやソフトウェアの利用規約、OSSライセンス、著作権などが問題ない形で、Hugging Face(注9)やGitHub(注10)、当社技術ブログ、GENIACコミュニティなどで順次公開予定です。また当社のAIサービスである「Fujitsu Kozuchi」に搭載していきます。
【商標について】
記載されている製品名などの固有名詞は、各社の商標または登録商標です。
【注釈】
注1
事業概要:
事業名:ポスト5G情報通信システム基盤強化研究開発事業/ポスト5G情報通信システムの開発(助成)
事業概要:ポスト5G情報通信システム基盤強化研究開発事業
https://www.nedo.go.jp/activities/ZZJP_100172.html
注2
スーパーコンピュータ「富岳」で学習した大規模言語モデル「Fugaku-LLM」を公開(2024年5月10日プレスリリース)
(https://pr.fujitsu.com/jp/news/2024/05/10.html)
注3
対話型生成AIの幻覚やAIを騙す敵対的攻撃に対処できるAIトラスト技術を開発し、「Fujitsu Kozuchi (code name) – Fujitsu AI Platform」で提供開始(2023年9月26日プレスリリース)(https://pr.fujitsu.com/jp/news/2023/09/26-1.html)
注4
スーパーコンピュータ「富岳」を用いてGraph500の世界第1位を獲得(2024年5月13日プレスリリース)
(https://pr.fujitsu.com/jp/news/2024/05/13-2.html)
注5
がんのタイプ分けなどのゲノム医療分野の課題を世界最高精度で解く、説明可能なAI技術を開発(2024年5月9日プレスリリース)
(https://pr.fujitsu.com/jp/news/2024/05/9.html)
注6
先端AI技術と「Fujitsu Uvance」のオファリングを融合させる、新たな全社AI戦略について(2024年2月14日プレスリリース)
(https://pr.fujitsu.com/jp/news/2024/02/14.html)
注7
対訳コーパス:
日本語と英語など、異なる言語の文と文を対訳の形でまとめた機械翻訳用のデータセット。
注8
指示学習:
新しいタスクに対する指示と回答例を一連の文章でLLMに与えて学習させる方式。
注9
Hugging Face:
世界中でAIのデータセットを公開するのに使われているプラットフォーム。https://huggingface.co/注10
GitHub:
世界中でオープンソースソフトウェアの公開に使われているプラットフォーム。https://github.com/
【関連リンク】
「ポスト5G情報通信システム基盤強化研究開発事業」の公募を開始します(令和6年2月16日)(METI/経済産業省)(https://www.meti.go.jp/policy/mono_info_service/joho/post5g/20240216.html)
GENIAC(METI/経済産業省)(https://www.meti.go.jp/policy/mono_info_service/geniac/index.html)
Fujitsu Kozuchi
(https://www.fujitsu.com/jp/services/kozuchi/)
【当社のSDGsへの貢献について】

2015年に国連で採択された持続可能な開発目標(Sustainable Development Goals:SDGs)は、世界全体が2030年までに達成すべき共通の目標です。当社のパーパス(存在意義)である「イノベーションによって社会に信頼をもたらし、世界をより持続可能にしていくこと」は、SDGsへの貢献を約束するものです。

【本件に関するお問い合わせ】
富士通コンタクトライン(総合窓口)
0120-933-200(通話無料)
受付時間: 9時~12時および13時~17時30分(土曜日・日曜日・祝日・富士通指定の休業日を除く)
お問い合わせフォーム(https://contactline.jp.fujitsu.com/customform/csque04802/873532/)
プレスリリースに記載された製品の価格、仕様、サービス内容などは発表日現在のものです。その後予告なしに変更されることがあります。あらかじめご了承ください。
引用